Prometheus告警与Alertmanager实战
Prometheus的告警分为两部分内容:
- Prometheus server中的告警规则、告警发送。
- 告警消息的处理程序Alertmanager,Alertmanager的主要功能包括告警消息的分组、路由分发、抑制和静默等核心功能
工作流程包括:
- 配置和启动Alertmanager
- 在Prometheus server中配置Alertmanager的地址,用于向Alertmanager发送告警消息
- 在Prometheus server中配置告警规则
一个简单版的Prometheus的架构图如下:
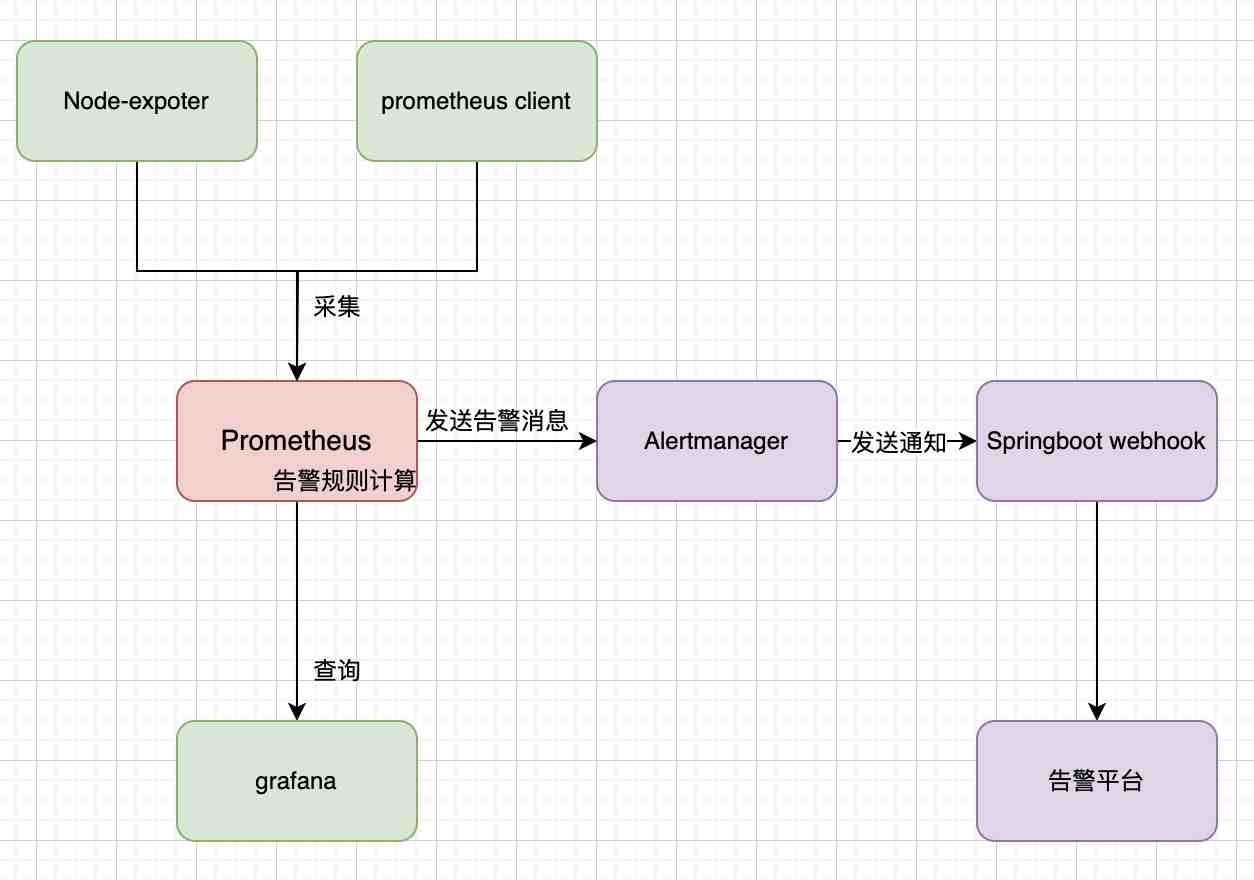
- Prometheus作为采集端,采集Node-exporter、sdk client的数据
- Prometheus作为存储端,起到了时序数据库的作用,存储采集到的数据
- 同时Prometheus读取告警规则文件,在进程内部计算告警规则,如果有告警发生,则向Alertmanager发送告警消息
- Alertmanager作为告警收敛的组件,在它内部进行告警消息的管理,最终将消息发送给第三方组件,通常是webhook
- 最后webhook发送给告警平台。
在前面的文章已经讲解过Prometheus采集数据和查询数据,在本篇文章中将会讲述Prometheus告警与Alertmanager实战。
Alertmanager介绍
Alertmanager处理来自客户端的告警消息,例如Prometheus server,包括消息的去重、分组、路由、抑制和静默等核心功能。先了解这些核心概念,然后通过配置文件的形式来具体讲解。
分组
分组是将同一组多个的相同的告警消息合并成一个高级消息。这在系统出现大量故障的时候非常有用,如果系统发出成千上万条相同的告警消息,对处理者来说是一个灾难。
比如,某个数据库出现网络故障,导致连接它的应用的几百个实例都出现异常,如果不进行分组合并,则会出现几百上千的告警消息,很可能淹没掉一些其他的告警消息,导致告警处理者漏处理一些告警消息,从而导致一些系统问题。
分组是
告警分组,告警时间间隔,以及告警的接受方式可以通过Alertmanager的配置文件进行配置
抑制
抑制是当某一告警已经发出,可以停止重复发送由此告警引发的其它告警的机制。
例如,当集群不可用访问出发了告警,通过Alertmanager的配置可以忽略与该集群有关的其它告警功能。这样可以避免接受一些与实际问题相关的告警。
静默
静默提供了一个标签匹配的设置,如果告警消息符合匹配,Alertmanager则不会发送消息到下游。
Alertmanager 通过配置文件去配置一些配置,然后通过命令行的方式的启动它。Alertmanager 可以在运行时重新加载其配置,通过向Alertmanager 进程发送 SIGHUP信号或者请求Alertmanager 的 /-/reload 接口(POST请求)。
Alertmanager安装
下载地址:https://prometheus.io/download/
启动alertmanager可以使用以下命令:
./alertmanager --config.file=alertmanager.yml
在启动之前,需要修改alertmanager的配置文件,默认的配置文件如下:
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
配置文件中包含了4个部分,分别是:
全局配置(global):用于定义一些全局的公共参数,如全局的SMTP配置,Slack配置等内容; 告警路由(route):根据标签匹配,确定当前告警应该如何处理; 接收人(receivers):接收人是一个抽象的概念,它可以是一个邮箱也可以是微信,Slack或者Webhook等,接收人一般配合告警路由使用; 抑制规则(inhibit_rules):合理设置抑制规则可以减少垃圾告警的产生
配置讲解
每个部分包含的可配置的参数很多,参数的配置会在以后的文章中讲解,在此篇文章只讲解最基础的和几个重要的配置:
gloabl配置
- resolve_timeout
当告警消息没有endTs这个时间戳参数时,Alertmanager会启动它的告警恢复逻辑。当启动告警恢复逻辑时,Alertmanager持续多长时间未接收到告警后标记告警状态为resolved(已解决)。这个对于prometheus的告警消息来说,它会含有endTs这个时间戳参数,所以这个resolve_timeout对于prometheus的告警消息是不生效的。
route配置
- group_by 默认alertname
The labels by which incoming alerts are grouped together.
将告警消息按照某个标签分组,比如按照alertname
- group_wait(default: 30s)
How long to initially wait to send a notification for a group of alerts. Allows to wait for an inhibiting alert to arrive or collect more initial alerts for the same group. (Usually ~0s to few minutes.) 一组告警第一次发送之前等待的时间。用于等待抑制告警,或等待同一组告警采集更多初始告警后一起发送。(一般设置为0秒 ~ 几分钟
- group_interval(default: 5m)
How long to wait before sending a notification about new alerts that are added to a group of alerts for which an initial notification has already been sent. (Usually ~5m or more.) 一组已发送初始通知的告警接收到新告警后,再次发送通知前等待的时间(一般设置为5分钟或更多)
- repeat_interval(default: 4h)
How long to wait before sending a notification again if it has already been sent successfully for an alert. (Usually ~3h or more). 一条成功发送的告警,在再次发送通知之前等待的时间。 (通常设置为3小时或更长时间)。
receivers配置
Receiver可以集成邮箱、微信、邮箱等,本文使用webHook的方式,即Alertmanager通过http接口调用来发送告警消息。
inhibit_rules 配置
抑制允许根据另一组警报的存在来静音一组警报。这允许在系统或服务之间建立依赖关系,以便在中断期间仅发送一组互连警报中最相关的警报。
当存在与另一组匹配器匹配的警报(源)时,禁止规则会静音与一组匹配器匹配的警报(目标)。目标警报和源警报在相等列表中的标签名称必须具有相同的标签值。
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
比如当发生severity=critical的告警时,会屏蔽掉severity=warning的告警,前提条件是两个告警的alertname、dev、instance的标签值相等。
根据实际情况,最终我的配置修改成如下:
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 30s
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:8080/webhook'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
重新启动alertmanager,获取通过热加载的方式重新加载配置文件。
在浏览器中访问localhost:9093,可以看到alertmanager的界面。
在prometheus中配置告警规则
在prometheus的启动程序的同级目录下面,建一个first_rule.yml的文件,这个文件是告警规则计算的配置,内容如下:
groups:
- name: test
rules:
- alert: HighQps
expr: sum(increase(prometheus_http_requests_total{handler="/metrics"}[1m])) > 1
for: 1m
labels:
severity: page
env: test
region: wuhan
annotations:
summary: HighQps
description: '{{ $value }}'
在告警规则文件中,我们可以将一组相关的规则设置定义在一个group下。在每一个group中我们可以定义多个告警规则(rule)。一条告警规则主要由以下几部分组成:
- alert:告警规则的名称。
- expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
- for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
- labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
- annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
在Prometheus的配置文件中,增加告警规则的配置:
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:909
rule_files:
- ./first_rule.yml
最好创建一个目录专门存储告警规则文件,然后用*.yml去配置所有的告警规则文件。
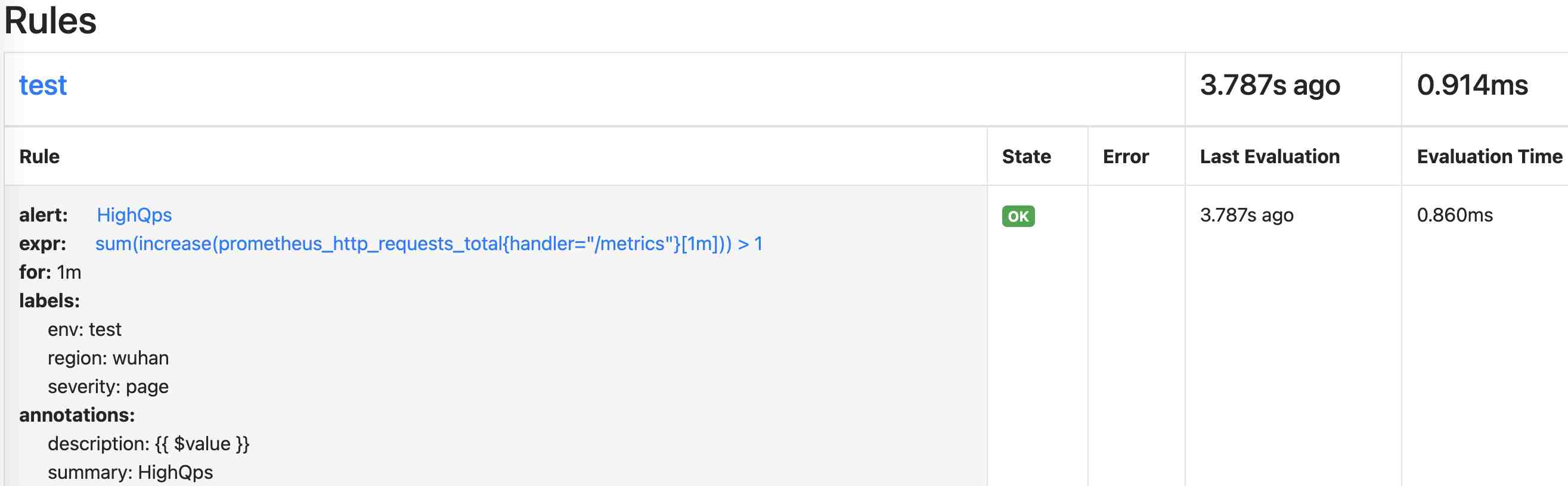
访问Prometheus的规则文件界面(http://127.0.0.1:9090/rules),可以看到的规则状态如下:
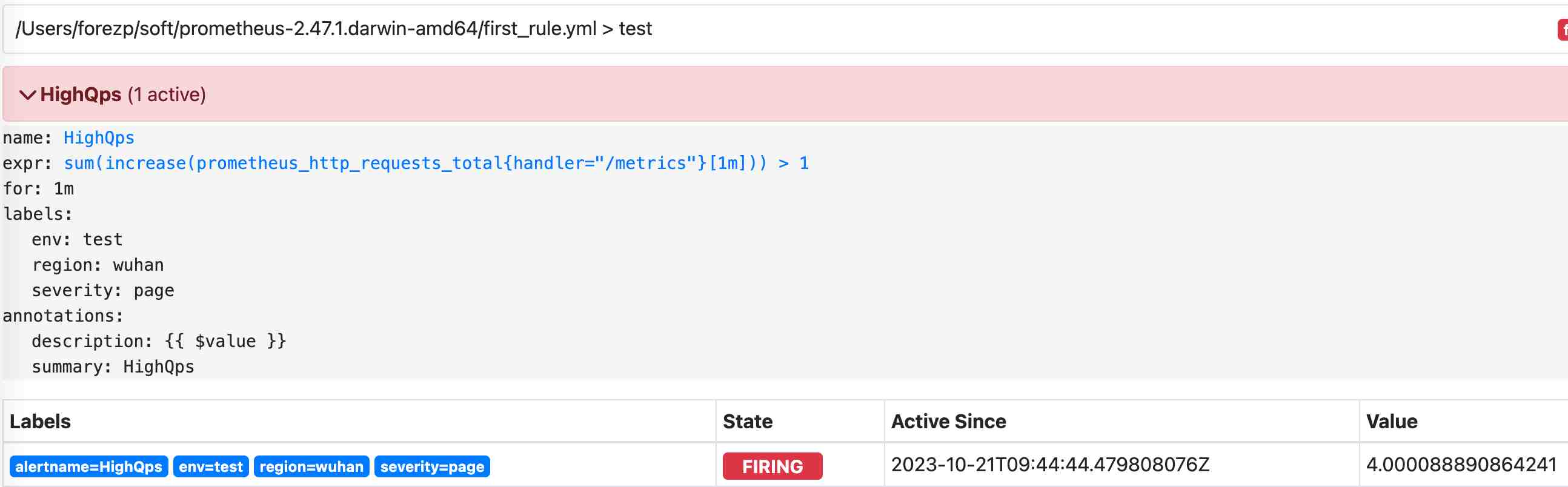
等待1分钟,访问Prometheus的告警页面界面(http://127.0.0.1:9090/alerts?search=),可以看到已经有一条告警消息已经发送给Alertmanager
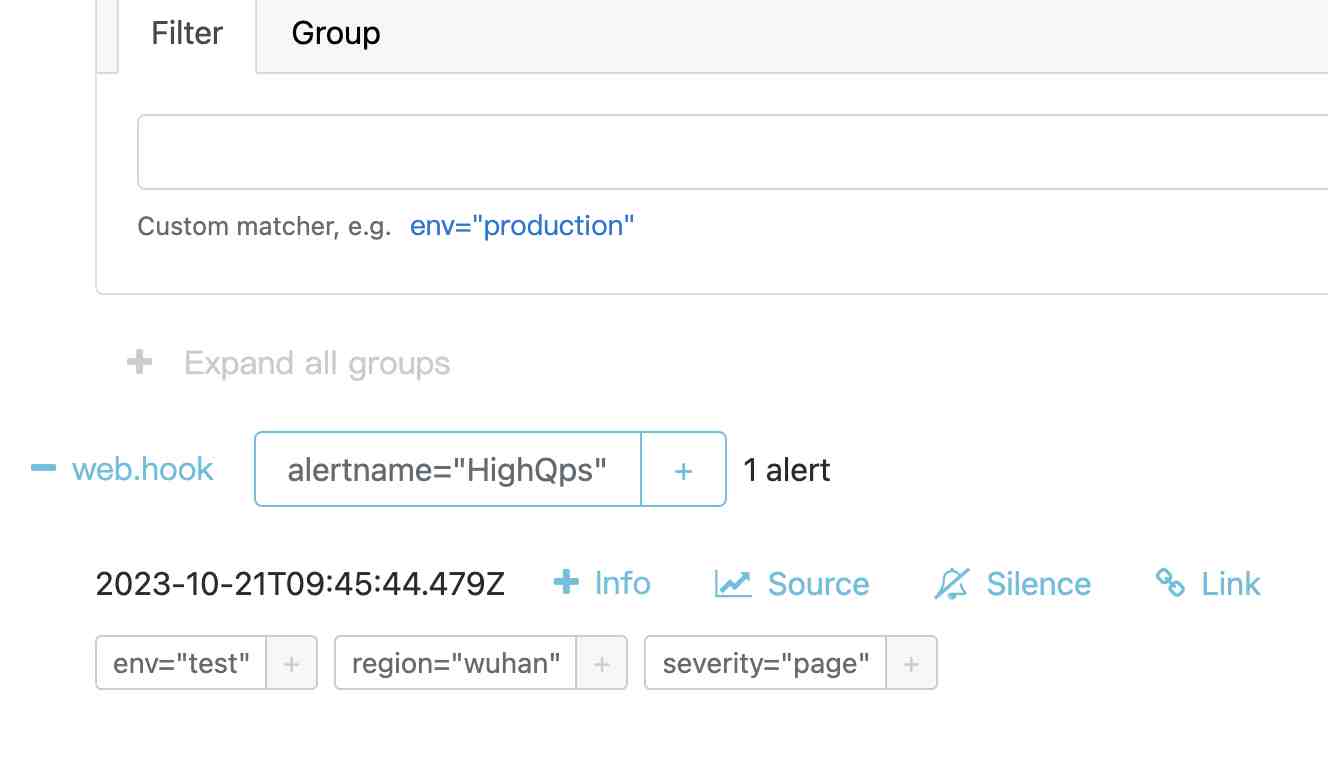
Alertmanager查看告警消息
访问alertmanager的界面(http://localhost:9093/#/alerts),显示告警消息已经收到:
webhook
Alertmanager收到告警消息后,如果判断需要发送消息给下游的Webhook程序,将通过POST的http请求发送下游程序,发送的告警消息的JSON格式如下:
https://prometheus.io/docs/alerting/latest/configuration/#webhook_config
{
"version": "4",
"groupKey": <string>, // key identifying the group of alerts (e.g. to deduplicate)
"truncatedAlerts": <int>, // how many alerts have been truncated due to "max_alerts"
"status": "<resolved|firing>",
"receiver": <string>,
"groupLabels": <object>,
"commonLabels": <object>,
"commonAnnotations": <object>,
"externalURL": <string>, // backlink to the Alertmanager.
"alerts": [
{
"status": "<resolved|firing>",
"labels": <object>,
"annotations": <object>,
"startsAt": "<rfc3339>",
"endsAt": "<rfc3339>",
"generatorURL": <string>, // identifies the entity that caused the alert
"fingerprint": <string> // fingerprint to identify the alert
},
...
]
}
对应的Java实体如下:
public class Webhook {
public String receiver;
public String status;
public ArrayList<Alert> alerts;
public Map<String,String> groupLabels;
public Map<String,String> commonLabels;
public Map<String,String> commonAnnotations;
public String externalURL;
public String version;
public String groupKey;
public int truncatedAlerts
public static class Alert {
public String status;
public Map<String,String> labels;
public Map<String,String> annotations;
public Date startsAt;
public Date endsAt;
public String generatorURL;
public String fingerprint;
}
}
在Springboot项目中,写一个接口如下:
@PostMapping("/webhook")
public String webhook(@RequestBody Webhook webhook) {
logger.info(webhook.toString());
return "ok";
}
这样webhook的程序收到告警消息后,就可以具体的执行告警逻辑,比如将告警消息发送给运维人员的邮箱。
参考文档
https://blog.csdn.net/qq_37843943/article/details/120665690
https://www.jianshu.com/p/c661e8050434
https://blog.51cto.com/starsliao/5763175
https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/alert/prometheus-alert-rule
